Availability of the component: Reference contacts are Thurid Vogt
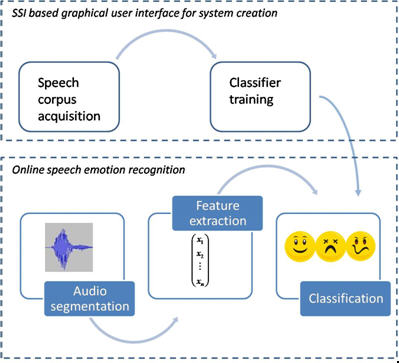
Notes: EmoVoice as toolbox for SSI is now available freely for download under the GNU Public Licences. All information on how to download EmoVoice are provided here A registration prior to the download is necessary. Combination of EmoVoice with SSI, includes modules for database creation; feature extraction + classifier building and testing; online recognition. Currently, there is no classifier or training data provided with EmoVoice: to create an own classifier based on self-recorded emotional speech corpus the SSI/ModelUI is also needed. The SSI Framework is a prerequisite to change or to recompile EmoVoice. Both the framework and ModelUI can be obtained from here.
Recently integrated into Smart Sensor Integration CALLAS toolkit, the component comes with a graphical user interface to record an emotional database reference for training a classifier tailored to a specific task: see also dedicated page
Besides functional tests, extensive experimentation in CALLAS is done in Scientific Showcases:
- the e-Tree : in this Augmented Reality art installation the component is used to derive emotional valence and arousal recognised from voice.
- the CommonTouch : the component is trained for affective input with a small group of users interacting and speaking in native French language as a preparation for an exhibition in Paris.
- for Interactive Digital Theater: in the Galaxies the component detects neutral, positive and negative emotions of people to influence the aestethic of the galaxies projected on the stage.
- for edutainment: in the Musickiosk the component is used in conjunction with a customised dictionary (Italian, French and English) for the words selected for the kiosk
Reference to the component and its usage can be found in CALLAS Newsletter3 and in the following CALLAS papers and articles:
- EmoVoice | A framework for online recognition of emotions from voice: Abstract
- Automatic Recognition of Emotions from Speech: A Review of the Literature and Recommendations for Practical Realisation: Abstract
- A systematic comparison of different HMM designs for emotion recongnition from acted and spontaneous speech: Abstract
- Exploring the benefits of discretization of acoustic features for speech emotion recognition: Abstract